| Umid-ii | Локализация | Клавиатура | Орфография | СЛОВАРЬ | |
| |
Транслитерация в латиницу | Конвертеры и декодирование | Редактор списков | Планы и развитие |
Словари в процессах обнаружения ошибок.Словарь - это исходный набор слов , необходимый для поиска и обнаружения ответов на поставленные к нему запросы. В данном случае словарь служит для сравнения ошибочных записей в документах пользователя. Какой должен быть объём словаря, чтобы его пользователь мог отслеживать допускаемые ошибки? Как определить его оптимальные размеры? Это очень спорный вопрос, и на него трудно дать однозначный ответ. Дело в том, что увеличение объёма словаря не гарантирует пользователя от возможных ошибок в проверяемых текстах. Если учитывать, что до настоящего времени нет у пользователя такого компьютера, который понимал бы смысл набираемых текстов. Всё, на что способен компьютер - это выполнить быстро задание по запрограммированному алгоритму. Это означает, что в предложении, содержащем фразу: пачка сигарет или почка сигарет, печка сигарет ошибок обнаружить он не сможет. Вывод прост - процесс обнаружения ошибок меньше зависим от количества слов в базе, в сравнении с алгоритмом анализа и обнаружения ошибок, а так же - от качественного состава словаря. Основным назначением данного словаря является оказание помощи при запросах для перевода с узбекского языка. При работе с текстом документа важно, быть уверенным в правильном изложении, что связано с необходимостью поиска и сравнения с образцовым написанием в "базе знаний". Как правило, пользователь обращается к словарю, не зная правописания нужного слова, или его толкования (перевода). Этот словарь решает такие проблемы Назначение словаря в комплексе программ.Главным назначением словаря является способность в нахождения
ответов на поставленные к нему запросы. Не мене значимым является возможность
обновления и сохранения обновленной информации.
Для этого в проекте UMID-II были реализованы следующие программные
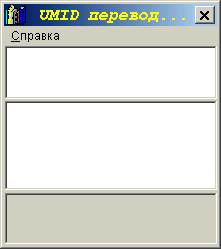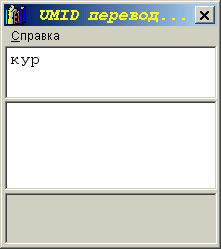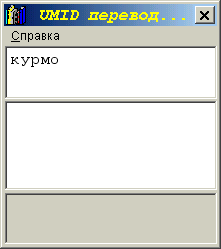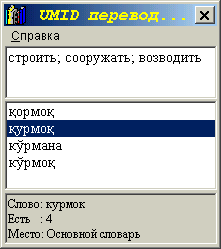
решения: На рисунке показан пример запроса с словарю: слово курмок выполняется заведомо с типичными ошибками. Однако, как можно видеть, словарь возвращает два варианта написания этого слова. При выделении слова из списка - получаем его значение перевода. Предварительный анализ ошибок при запросах к "базе знаний" позволил использовать это приложение по своему прямому назначению - возвращать необходимые варианты ответов. Основной словарный запас для "базы" UMID-II был сформирован на проверяемых текстах документов и методических руководств, публикуемых в юриспруденции. Много слов заимствовано из Законодательных актов. Остальные, необходимые для анализа, словоформы будут пополняться программно из Ваших документов в процессе проверки ошибок. При инсталляции комплекса программ UMID у Вас на компьютер подгружаются начальная "база знаний" которая состоит из пяти списков словарей:
Все словари, при инсталляции приложения, имеют первоначальные записи, которые остаются у пользователя и после де инсталляции (удаления) комплекса программ. При всех последующих установках программы UMID-II, она работает со списками, которые были оставлены ранее. Таким образом каждый пользователь будет иметь свою индивидуально развиваемую "базу знаний", содержание которой отражает профессиональную специализацию и интеллект пользователя.
Главные отличия от аналогичных приложений.Здесь Вы можете набирать слово, даже не зная его правописания. Попробуйте, к примеру, найти в словаре из 80000 слов, слово хукукий, в котором Вам не известно его написание. Это слово состоит из пяти букв, которые могут писаться с элементом и без него. Используя несложные вычисления, получим 5^2 = 25 число вариантов при просмотре значений в словаре. UMID все комбинации символов обнаруживает моментально. При обращении к словарю (при вводе с клавиатуры, или перетаскиванием "мышкой" прямо из документа в WORD) слово проверяется во всех списках, при этом делается предположение, что записанное слово может содержать ошибку. Исследуются все возможные комбинации кодов. Результаты выводятся в списке диалога на форме. Это его главное отличие от аналогичных электронных словарей позволили с уверенностью именовать - орфографическим.
Перспективным направлением развития этого приложения считается
дальнейшее обновление новыми возможностями:
|
ВРЕМЯ, НЕ ЖДЁТ.. Вы можете высказать свои замечания автору проекта Комплекс программ UMID-II, посетив открытый форум.
Если Ваше
предложение окажется
конструктивным, то Вы вправе рассчитывать
на вознаграждение. Для подробного изучения состава проекта Вы можете скачать его описание - 200k
|
|||||||
|
|
{kind=link}