| Umid-ii | Локализация | Клавиатура | ОРФОГРАФИЯ | Словарь | |
| |
Транслитерация в латиницу | Конвертеры и декодирование | Редактор списков | Планы и развитие |
Введение.При проверке ошибок в любом тексте происходит сравнение кодов проверяемого символа в слове с его образцовым написанием из словаря, графическое изображение этого символа при этом не принципиально. До недавнего времени, все тексты в разных организациях выполнялись различными типами шрифтов, с использованием применявшихся в них кодов для "кириллицы" узбекского языка. Позиции (нумерация) кодов символов в этих шрифтах мало кого беспокоила, главным было – отпечатать текст на узбекском языке правильным. Развитие компьютерных технологий вызвали потребность файлового обмена документами. Возникает необходимость в совместимости документов на уровне кодов, что подразумевает - использование единой системы кодирования символов как в кодовой таблице, так и в шрифтах. Всё это относится только к изображениям литер узбекского языка (символов "с элементом"). Поэтому для правильного исполнения проверки ошибок в документах, выполненных на разных компьютерах, с их различной конфигурацией, необходима единая система кодирования национальных символов . За основу предлагается принять, используемую в WINDOWS-NT - систему Unicode (Юникод). Эта же система кодировок используется и в последней версии Windows-2000,Windows XP, для кодов литер узбекского алфавита. Проверка орфографических ошибок в комплекс UMID ведётся в соответствии нумерацией кодов символов, используемой в этих таблицах. А что делать, если уже текст набран «своим» шрифтом? Пришлось бы потрудиться, нужно было бы любым доступным для Вас способом заменить все неправильно отображаемые литеры в этих текстах на правильные их изображения в шрифтах от Windows XP. Решения такой задачи в составе комплекса UMID становится тривиальной. Встроенная функция "Исправление кодировки", заменит коды литер в текстах использующих «ваши» шрифты, на соответствующие коды символов, предложенные в Windows-XP. Теперь Ваш документ будет представлен системными шрифтами и совместим для обмена. Решаемые задачи.Программа UMID - это универсальное приложение, которое служит для выполнения задач по переводу текстов в представление на латинской графике. Для правильного решения этой задачи необходим текст, не содержащий орфографических ошибок с соблюдением принятой кодировки для дополнительных символов узбекского алфавита. В режиме проверки ошибок Вам предоставляются следующие возможности:
Как видите - это стандартный набор функций, необходимый для правки ошибок, но для узбекского языка. Здесь также можно:
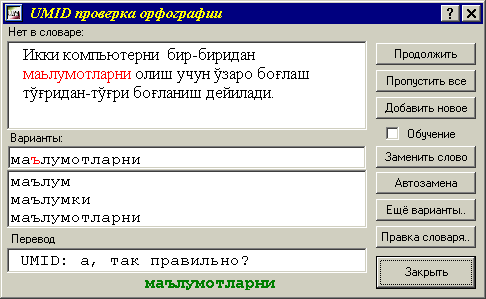
Все вышеперечисленные функции позволят Вам подготовить документ на узбекском языке с использованием символов латинской графике, с максимальной гарантией отсутствия орфографических ошибок. WEB и издательство.Не секрет, что для публикаций в интернет много печатного материала попадает из сканированных документов. Этот процесс порождает массу скрытых проблем, также как и для издателей. Одна из таких проблем в подробностях рассматривается в этом разделе. По ряду причин (отсутствие стандарта на дополнительные литеры узбекского алфавита, отсутствие локализации ОС и др.) программы, используемые пользователями для распознавания символов в текстах после сканирования, часто работают не верно. Возникающие при этом недоразумения, приводят к проблемам при проверке ошибок и, как правило, отражаются на процессах транслитерации. Вы не раз, встречались с ошибками такого плана. Как, например, можно отличить написание таких символов в латинице, как: a, c, o, р, е, y x (и в кириллице а, с, о, р, е, у, х). Они не различимы в текстах, но окажут своё определённое влияние на процессы перевода текста на узбекском языке в его представление с отображением в латинице. Вопросы анализатора ошибок, адресованные к пользователю, проверяющему свой текст, обычно игнорируются. Слово, которое он (она) видит в диалоговом окне написано "правильно". Для примера, рассмотрим такой случай : программой обнаружена ошибка (литера с - была записана в латинице) в слове асосан. При проверке ошибок программа остановилась на этом слове с указанием на ошибку, не обнаружив этого слова в "базе", а пользователь записал(а) его в словарную "базу", как новое слово с переводом. Теперь эта ошибка стала бы распространяться во всех текстах, автоматически предлагая замену слово с неправильной литерой. Данная проблема в правописании, рассматривается анализатором ошибок UMID-II, который умеет обнаруживать такие ошибки. При попытке записать такое слово в "базу", он укажет Вам на допущенные неточности в прямо в предлагаемом Вами варианте слова. Если, после исправления ошибки, это слово будет обнаружено в словаре, то вариант этой записи будет выведен на экран диалоговой формы. Программа UMID-II гарантирует, что допускаемые ошибки при распознавании текстов на узбекском языке будут выявлены и исправлены на начальной стадии их образования. Это свойство положительно отразится в последующих переводах таких документов в представлении на латинице. Как это работает.Проверка орфографии выполняется автоматически. Если Вы предварительно не выделяли фрагмент для проверки, то проверяется целый документ. Как это происходит? Из текста программой выделяется одно целое предложение, выделяется слово на узбекском языке, отыскивается его "двойник" в базе. Если такое слово не обнаружено, ведется поиск возможных вариантов в списках для авто замены. При отсутствии результата поиска, делается предположение, о допущении ошибки в написании. Проводится анализ, включающий в себя ряд необходимых манипуляций над этим словом, по заданному алгоритму поиска допускаемых изменений и последующей выборкой результатов для представления пользователю. После завершения анализа выбирается одно слово из списка предполагаемых замен, и делаются исправления.
Ввиду того, что UMID - это обучаемая программа, "он" запрограммирован на то, что пользователь (человек) - всегда прав и тоже может ошибаться... Таким образом, Вы не ограничиваетесь в выборе принятия окончательного решения. Вы можете принять предложенный вариант, или выбрать из списка более правильное решение. Вы можете внести свою коррекцию в слове, руководствуясь внутриведомственными тематическими словарями, и добавить его в словарь, как новое с переводом. Таким способом, вы сможете обучить UMID, постоянно доводя его встроенные возможности до необходимого уровня знаний. На форме этого приложения имеется ключ "Обучение", позволяющий программе запоминать все новые словоформы и варианты их правописания. Этот режим позволит пополнять базу знаний UMID словами , в правописании которых Вы не сомневаетесь. Эти слова будут записываться в список с "Вашей лексикой". Для принятия правильного решения Вам предоставляется список "слов-подсказок" с переводами на русский язык. В базу слово попадёт, если оно не было обнаружено ни в одном из списков слов. Слова в списке "Ваша лексика" в качестве перевода имеют символ (*), который в любое время может быть заменён Вами необходимой строкой с переводом. При следующем сеансе работы - обнаружив слова с переводом UMID самостоятельно перепишет их в список новых слов от пользователя. Таким образом, обучаясь "он" помогает Вам поддерживать порядок в базе. Напоминаю, что все новые слова и списки словарей оставляются на диске даже после полной де инсталляции комплекса. Это позволяет Вам обновлять программное обеспечение и при этом сохранить наработанный лексический материал и постоянно «наращивать» способности UMID. Программа, каждый раз, приостанавливает свои действия, после обнаружения слова, из-за неоднозначности (наличие нескольких вариантов) в его правописании. Вам предоставляется право выбора правильного варианта изложения. Щелчком по кнопке "Заменить", Вы заставляете программу выполнить ваше решение. При включенном режиме "Обучение" программа запомнит эту словоформу в список с "Вашей лексикой". Впоследствии, изучая арсенал Ваших действий, программа без труда будет распознавать все повторяющиеся ошибки в словах. Список слов, полученный в результате обучения, можно редактировать из режима "Правка словаря".
Проблема на данном этапе обработки документа на узбекском языке осложнена ещё и способами используемого форматирования. Вы замечаете разницу представления документов в WORD, которая зависит от используемой версии 8.0, 9.0, или 10. Если визуально документ можно "подогнать" для правильного отображения, то его структурное построение - это задача посложнее. Вот здесь и кроются ошибки, из-за которых возникают проблемы при обработке документа. Для примера приведу часто встречающуюся конфигурацию компьютера, когда исходный текст на узбекском языке, содержание которого создавалось на компьютере со слабым процессором (x486), где была установлена WINDOWS 98SE и OFFICE-97. Помимо различной кодировки символов, здесь применялись "старые" тэги (спец.коды RTF) форматирования. При открытии такого документа приложение WORD пытается воссоздать приемлемый вариант документа для правильного отображения. Вы это можете ощутить, по длительности открытия документа. Допустим, Вы решили исправить в таком документе ошибки, или отредактировать его текст, при этом Ваш компьютер - это уже Pentium-IV, с установленным OFFICE-XP. После редактирования Ваш текст в документе будет содержать смесь кодировок ANSI и Unicode, т. к. это два, действующих до настоящего времени, стандарта. Этот документ, возвращённый пользователю компьютера, где установлена OFFICE-97 будет отображён неправильно. Эти ошибки в кодах можно обнаружить и при просмотре скопированного текста в "Блокноте", который может отображать текст, только в одном из двух вариантов. Часть символов из алфавита узбекского языка в этом тесте будут отображены не правильно. Комплекс программ UMID-II решает эти проблемы и многие другие, которые возникают у пользователя при работе с документами на узбекском языке.
|
ВРЕМЯ, НЕ ЖДЁТ.. Вы можете высказать свои замечания автору проекта Комплекс программ UMID-II, посетив открытый форум.
Если Ваше
предложение окажется конструктивным, то Вы вправе рассчитывать
на вознаграждение. Для подробного изучения состава проекта Вы можете скачать его описание - 200k |
|||||||||
|
|
{kind=link}